春节之前,希捷固件门事件闹得沸沸扬扬,事件的起因是由于部分希捷7200.11系列硬盘出现“卡死”、瞬间丢失等问题,有关事情详细信息、以及受影响的硬盘型号,可阅读《30款硬盘有问题!细看希捷固件门事件》一文。虽然官方称受影响的硬盘主要是12月份生产的那批次,可能会造成数据丢失,但该问题影响了用户的日常使用。当时希捷方面表示,通过刷写固件可以解决该问题,但数据无法保证不丢失.
当我们在高兴中度过春节时,希捷方面一直为解决问题而努力,经过一波三折(期间曾经放出新固件下载,但用户发现该固件会产生新的问题,因此希捷马上撤下),最近终于开放正式版固件给用户下载,通过刷写相应的固件,便可解决此问题。

部分出问题的希捷7200.11 500G
虽然希捷给出了新固件下载,并在其官方网站作出详细说明,但为使受影响用户便于操作,同时为验证固件是否会影响硬盘性能,我们将通过实战向大家展示硬盘固件升级的过程,希望对受此问题困扰的用户有所帮助。在进行刷写固件之前,我们需要先做一些准备工作。
注意:刷写固件存在一定风险,请三思而后行,有条件的话请进行数据备份,数据无价!如果硬盘正常使用,没出现上述问题,建议不要升级固件。如果数据很重要请与我们直接联系,我们可以100%恢复这种7200.11硬盘数据.并修复好固件问题.
检测硬盘型号、下载相应固件
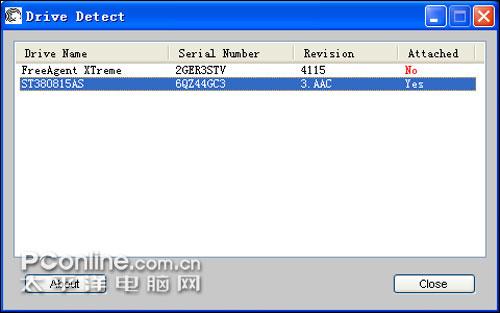
在刷写固件前,首先要确定自己的硬盘型号,希捷给出了硬盘型号检测工具,通过它可查看到硬盘型号、固件版本号等信息。
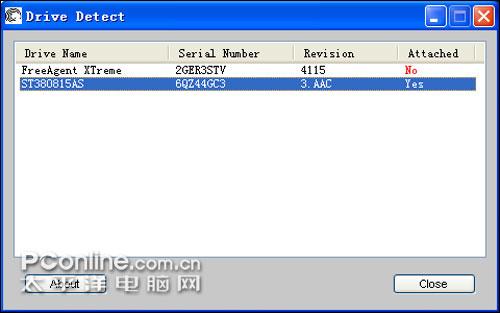
硬盘型号检测工具
上面就是希捷提供的硬盘型号检测工具,其中Drive Name就是硬盘型号,Serial Number是硬盘序列号,Revison是固件版本号,Attached表示是否有连接起来,并非表示是否中招了,这点是需要注意的。Drvie Name即是硬盘型号,例如“ST3500320AS”,然后找出对应的固件下载。由于希捷表示只有部分7200.11硬盘受到影响的,如果正在使用的7200.11硬盘没出现“卡死”、“丢失”的问题,则无需更新固件。如想为进一步确认硬盘是否受到影响,可进行下面的操作。
1、输入硬盘型号(如ST3500320AS,即工具查到的Drvie Name):
http://support.seagate.com/modelcheck/modelcheck.jsp
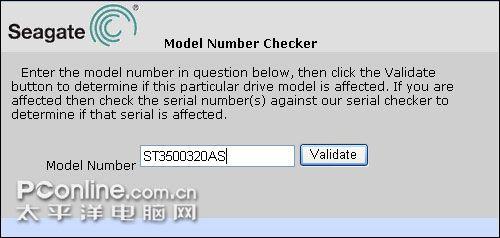
输入硬盘型号
2、输入硬盘序列号和验证框的信息(如9QM9NHVR,即工具查到的Serial Number):
https://apps1.seagate.com/rms_af_srl_chk/
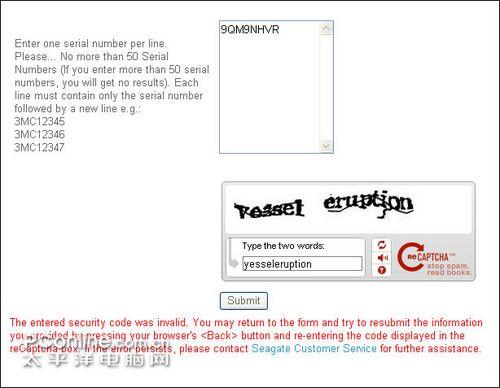
输入硬盘序列号
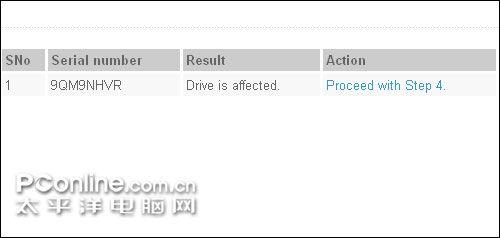
硬盘受到影响,需要升级
如果结果显示为“Drive is affected”,表现受到影响,可升级固件解决问题。升级固件需要用到刻录机或软驱,下面是各型号的固件地址:
希捷酷鱼 7200.11系列:
希捷 7200.11 160G:ST3160813AS 固件ISO镜像下载:
http://support.seagate.com/firmware/Brinks-1D1H-SD2B.ISO
希捷 7200.11 320G:ST3320613AS、ST3320813AS 固件ISO镜像下载:
http://support.seagate.com/firmware/Brinks-1D2H-SD2B.ISO
希捷 7200.11 500G:ST3500320AS、ST3500620AS、ST3500820AS 固件ISO镜像下载:
http://support.seagate.com/firmware/MooseDT-SD1A-2D-8-16-32MB.ISO
希捷 7200.11 640G:ST3640323AS、ST3640623AS 固件ISO镜像下载:
http://support.seagate.com/firmware/Brinks-2D4H-SD1B.ISO
希捷 7200.11 750G/1T:ST3750330AS、ST3750630AS、ST31000340AS 固件ISO镜像下载:
http://support.seagate.com/firmware/MooseDT-SD1A-3D4D-16-32MB.ISO
希捷 7200.11 1T:ST31000333AS 固件ISO镜像下载:
http://support.seagate.com/firmware/Brinks-3D6H-SD1B.ISO
希捷 7200.11 1.5T:ST31500341AS 固件ISO镜像下载:
http://support.seagate.com/firmware/Brinks-4D8H-SD1B.ISO
希捷酷鱼 ES.2 SATA系列:ST3250310NS、ST3500320NS、ST3750330NS、ST31000340NS
需要查看硬盘标签上的P/N序列号,然后进入下面的地址,找到对应的固件进行升级,如当前硬盘固件版本为SN06或SN16,则不需要升级。
http://seagate.custkb.com/seagate/crm/selfservice/search.jsp?DocId=207963&NewLang=en
迈拓 DiamondMax 22系列:
迈拓 DiamondMax 22 160G:STM3160813AS 固件ISO镜像下载:
http://support.seagate.com/firmware/Brinks-1D1H-MX1B.ISO
迈拓 DiamondMax 22 320G:STM3320614AS 固件ISO镜像下载:
http://support.seagate.com/firmware/Brinks-1D2H-MX1B.ISO
迈拓 DiamondMax 22 500G:STM3500320AS 固件ISO镜像下载:
http://support.seagate.com/firmware/MooseDT-MX1A-2D-DMax22.ISO
迈拓 DiamondMax 22 640G:STM3640323AS 固件ISO镜像下载:
http://support.seagate.com/firmware/Brinks-2D4H-MX1B.ISO
迈拓 DiamondMax 22 750G/1T:STM31000340AS、STM3750330AS固件ISO镜像下载:
http://support.seagate.com/firmware/MooseDT-MX1A-3D4D-DMax22.ISO
迈拓 DiamondMax 22 1T:STM31000334AS 固件ISO镜像下载:
http://support.seagate.com/firmware/Brinks-3D6H-MX1B.ISO
实战!刷写硬盘固件
刷写此硬盘固件需要有刻录机,把刚才下载到的固件ISO镜像,用Nero、UltraISO、Alcohol等刻录软件把镜像刻录到一张空白的CD-R/CD-RW上,当然也可以把它制作成DOS启动软盘,不过现在恐怕有软驱的用户所剩不多了吧。再提醒一下,刷写固件存在一定风险,请三思而后行,有条件的话应进行数据备份。
确保主机内除了要刷写的硬盘和光驱外,没有其他SATA/IDE设备。进主板BIOS,设置成光驱启动,放进刻好的光盘。一切准备好后,刷写开始,Let's go!
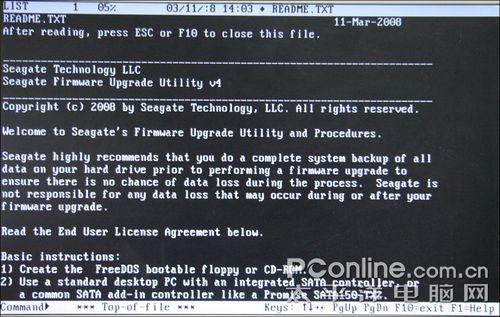
刷写固件的说明
用刚制作的光盘启动后,会出现上图所示的Readme说明,相信大家都没什么耐性和恒心把它看完的,呵呵。直接按ESC或者F10进入下一步操作。
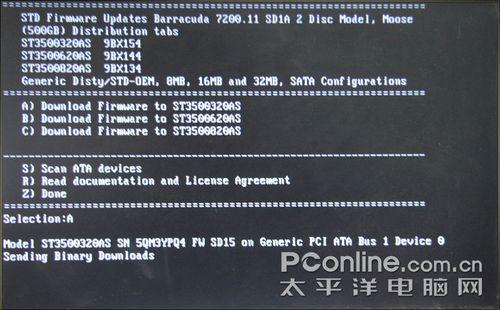
操作界面
上图是正式的操作界面,显示当前固件适用的硬盘型号,按相应的字母进行操作。相信大家还记得之前查看到的硬盘型号吧,万一忘记了,选择“S”,进行硬盘扫描,可查看到硬盘型号。
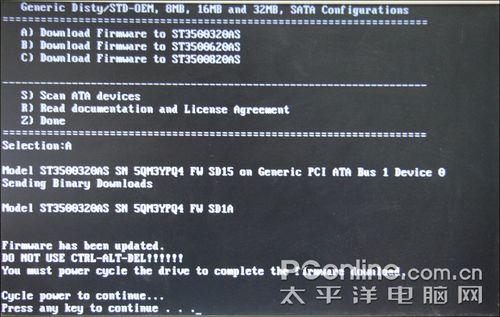
刷写完毕
由于笔者进行测试的是希捷 7200.11 500G硬盘,型号为“ST3500320AS”,因此选择“A”。然后程序就开始进行固件刷写操作,此时切勿断电。待固件升级完毕后,会有提示出现。需要注意的是,和刷写显卡、主板BIOS不同,此时不能按“Ctrl+Alt+Del”重起电脑,按下任意键继续,电脑会自动关机,等待10来秒再开机,完成整个固件刷写过程。
刷写固件前后硬盘性能比较
早在希捷7200.11 1.5TB硬盘出现固件缺陷时,就有用户联系希捷拿到固件,但有用户反映刷写固件后,硬盘性能有所降低,是否真的是这样呢?我们用著名的磁盘检测软件HD Tune硬盘进行性能测试,以考察刷写固件前后的硬盘性能变化,是不变?还是提升?又或者是降低呢?下面将为大家解答。
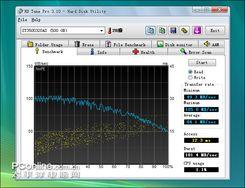
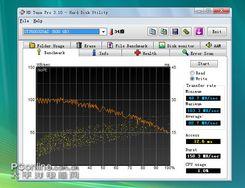
刷写固件前读取/写入测试
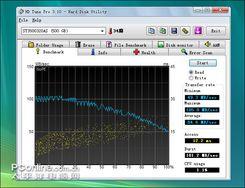
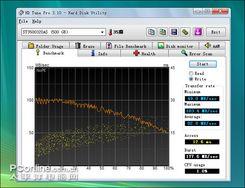
刷写固件后读取/写入测试
从测试图可以看到,无论读取还是写入,刷写固件前后性能基本没有变化,也表明了此固件只是修复BUG,并不会对硬盘性能造成影响
总结
希捷固件门事件终于告一段落
在固件问题大规模出现后,希捷方面也一直在积极跟进。最近希捷终于公开固件下载,硬盘出现问题的用户只需下载固件,并进行刷写即可解决问题,而刷写过程也并不复杂。从刷写固件前后的对比测试可看出,刷写新固件并不会影响磁盘性能。
我们到卖场随机拿了一个新上市的希捷7200.11硬盘,并到希捷官网进行查询,结果表明该硬盘已不存在固件问题。这样,希捷固件门事件可以说告一段落了,但这次出问题的硬盘型号多达30款,涉及范围非常广,对很多用户造成困扰,也有网友称已对希捷失去了信心。针对这个事情,硬盘厂商应吸取教训,在竞争过程中应把硬盘质量放在首位,毕竟硬盘不同于其它硬件,对一般用户而言,硬盘出问题就意味着数据丢失,谁为他们无价的数据买单呢?毕竟硬盘有价,数据无价啊.
相关的主题文章: